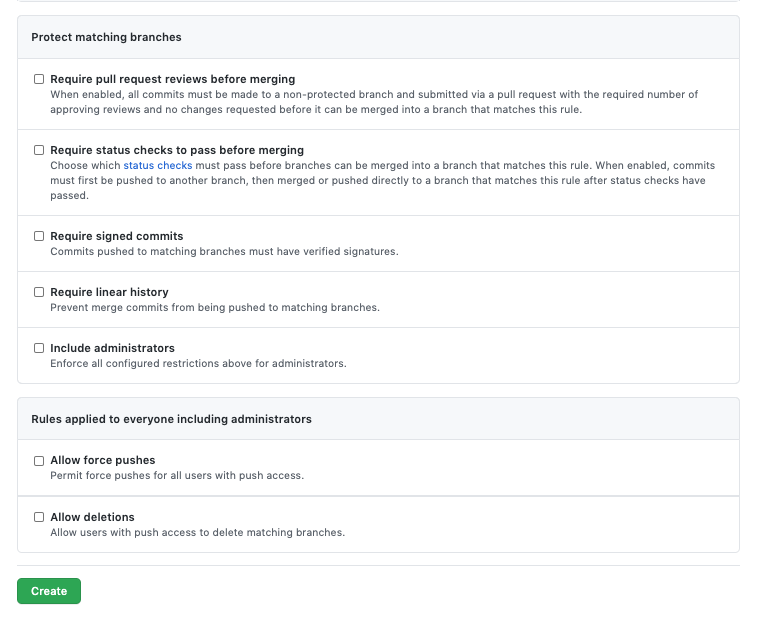
I’m something of an Apple laptop advocate.
I’m not, however, hugely into the Apple eco-system; I don’t own, and have never owned, an iPhone, iPod, iMac, iWatch, or some of the other things. I do, however, own an old iPad with a cracked screen that was particularly cheap, and I got a free AppleTV a short while back. I’m a pragmatist deep down, so I tend to favour the best tool for the job, rather than fashion and so on.
A few years ago I moved to a MacBook Pro for development and never looked back. I recently had to switch back to Windows briefly, due to my older work MBP failing over the Christmas period, and quickly became frustrated at how protracted certain things were that are just simpler to accomplish on a Mac.
This works both ways, though. As a pragmatist, I can’t help but miss certain ‘things’ on Windows that are, perhaps, missing or simply different on a Mac for various reasons.
Luckily, AppleScripts and Automator make it possible to ‘add’ that functionality back in.
Sharing File Paths
In the development world, most things are normally going to exist on, or be deployed to, a *NIX type system. It’s one of the thing I like about MacOS – you have the advantages of a Linux type system, without the compatibility issues of being purely on Linux. It does, evidently, become an issue when you have Windows users (Muggles, if you like) in your work eco-system. Sharing a file path will, in native OS terms, mean that your slashes are the wrong way round.
It’s easy in windows to just user the address bar to get a file path, like so.

You can, of course, enable the ‘Path Bar’, which allows you to context click on a directory to get the Pathname, but it doesn’t work as easily with files (especially if I want to reference a configuration file in a script quickly), so this solution suits both usages.
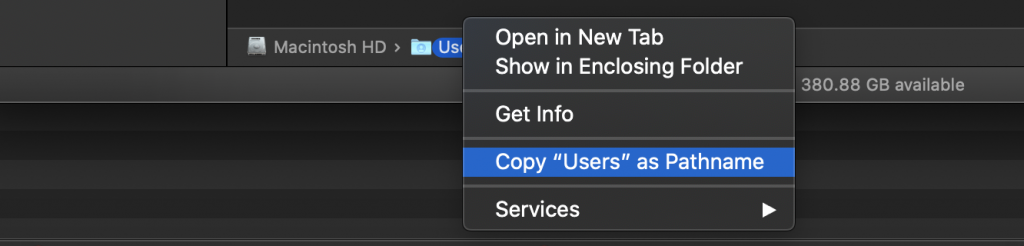
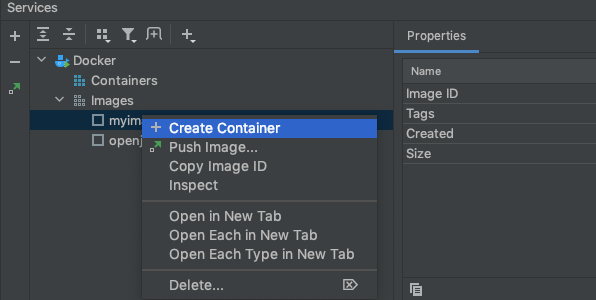
Adding a ‘Copy File Path’ context menu option
To start off, we need to open ‘Automator’.
Within Automator, select ‘Quick Action’

Next, set the Workflow to receive ‘files or folders’ in Finder.app

Then select ‘Copy to Clipboard’ as the action by dragging it into the workspace area.

You should now be able to Save this as a Quick Action. The name you choose here will reflect how it is displayed in the context menu, so choose something based on that outcome.

Adding a ‘Copy File Path’ context menu option with Windows-style slashes
Following the above steps, you can now select ‘Duplicate’ to make the next action:

This will keep everything including the ‘Copy to Clipboard’ step. We’re going to add a ‘Run AppleScript’ action that comes after that.

In the AppleScript editor window that appears, paste in the following:
on fixpath(macpath, search, replace)
set OldDelims to AppleScript's text item delimiters
set AppleScript's text item delimiters to search
set newText to text items of macpath
set AppleScript's text item delimiters to replace
set newText to newText as text
set AppleScript's text item delimiters to OldDelims
return newText
end fixpath
get the clipboard
set macpath to the clipboard
set macpath to fixpath(macpath, "<", "")
set macpath to fixpath(macpath, ">.", "")
set macpath to fixpath(macpath, ">", "")
set macpath to fixpath(macpath, "smb://", "\\\\")
set macslash to "/"
set winslash to "\\"
set winpath to fixpath(macpath, macslash, winslash)
set the clipboard to winpathYou can add other ‘set macpath’ clauses for replacing specific drive/folder references if you wish.
You can now save this variation as a different Quick Action, e.g.

You should now be able to see your options in the context menu, under ‘Quick Actions’ when selecting a file:
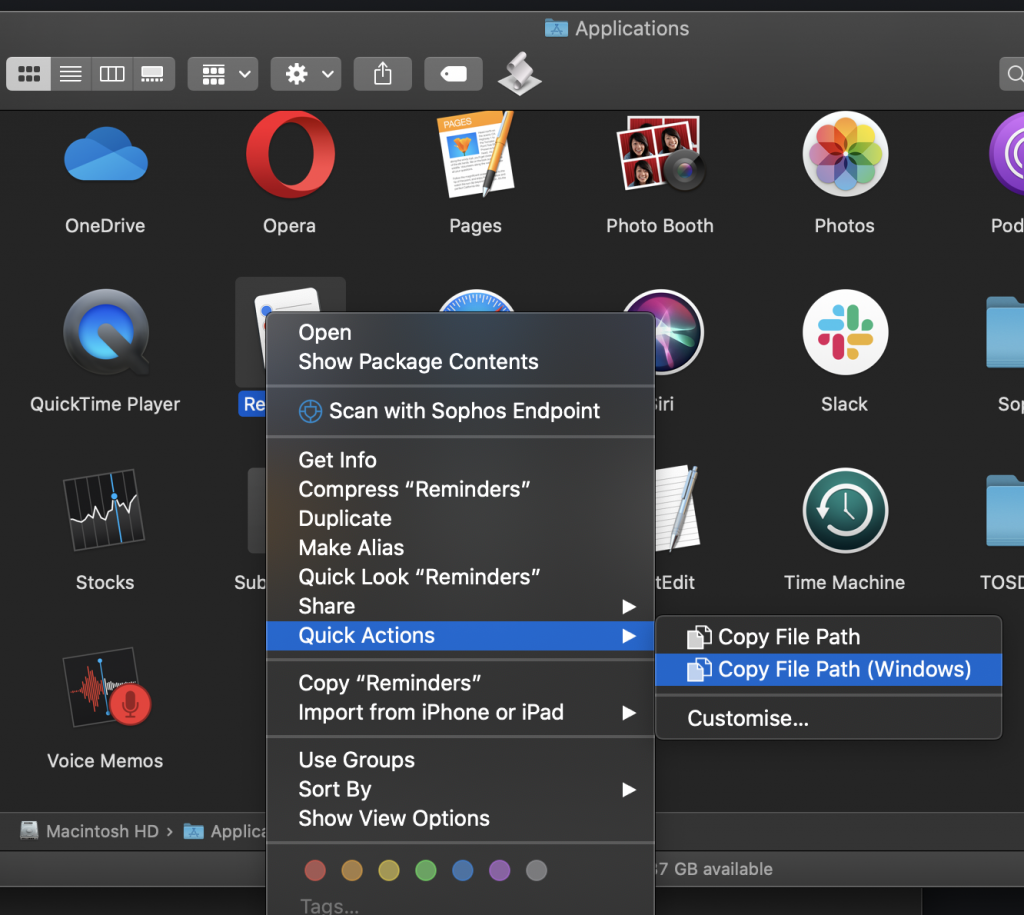
The result of the above being:

Refreshing the Finder Window
Another annoyance is when something other than Finder changes/amends the directory structure – Finder doesn’t ‘update’ to know about it. This happens a lot with development and can make things frustrating.
Unfortunately, there isn’t a default Finder ‘refresh’ button like you get in Windows, but you can add one.
To do this, open Script Editor:
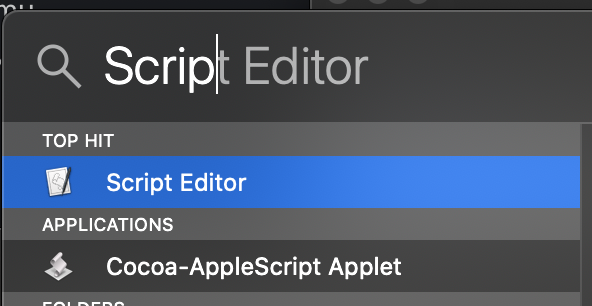
Then, paste the following snippet into the editor.
tell application "Finder" to tell front window to update every item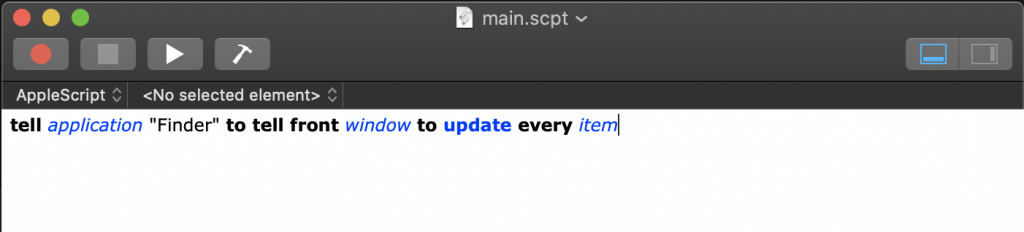
Now, choose File > Export, then select ‘Application’ as the File Format:
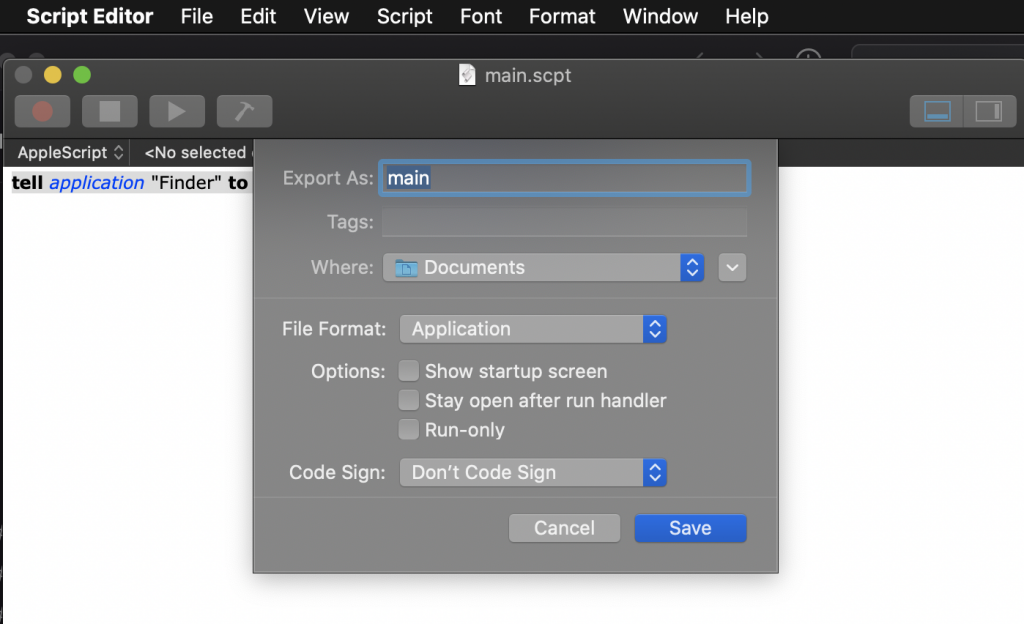
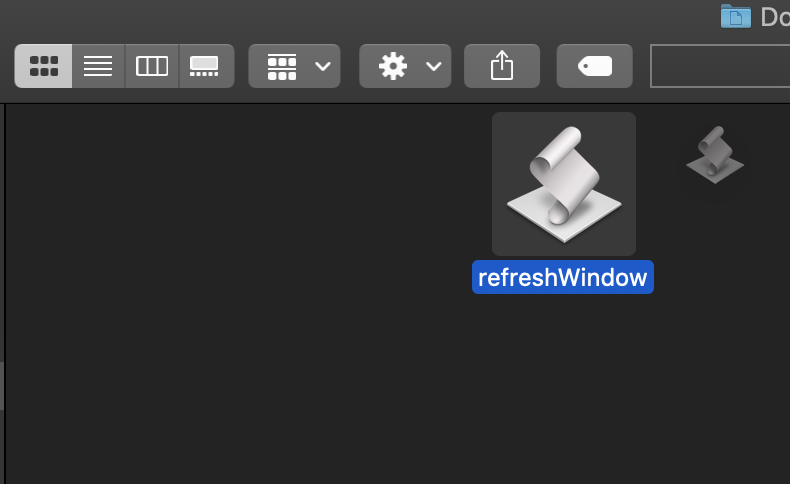
You should then have an Application file in the target folder.
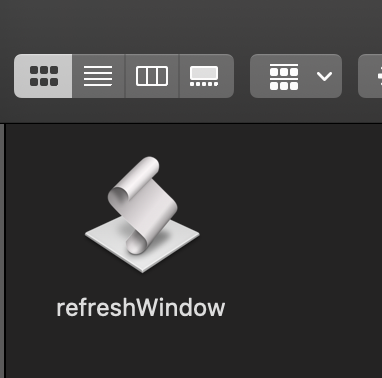
If you hold the Command button, you can now drag this to the toolbar.
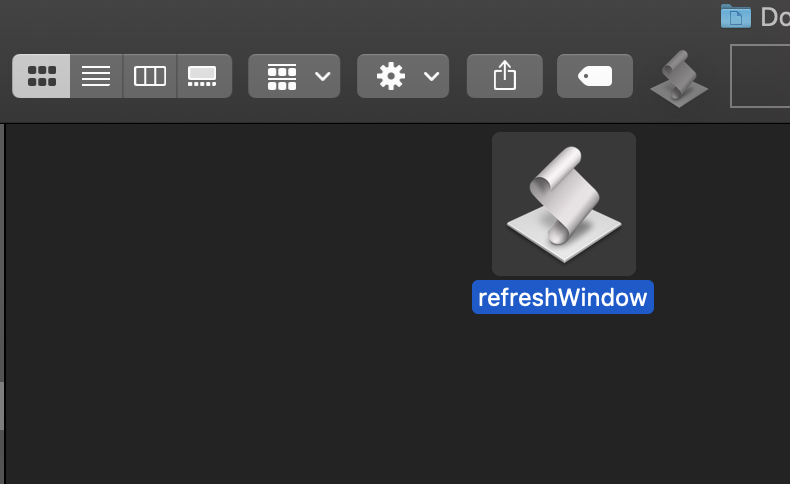
You can now use that button to refresh Finder, and update the directories for any changes that have occurred that Finder isn’t aware of.
You can, if you wish, open the package and change the icon. This can be used to make a ‘prettier’ button.
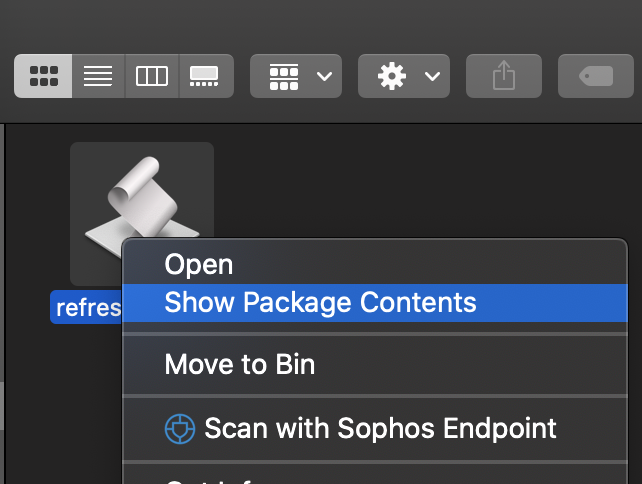
You can move the button at any time by holding command and dragging it back off the toolbar – useful if you want to experiment with the icon.